Twist Biosciences: The DNA API
Alex Danco's Newsletter, Season 3 Episode 20
Hello everyone!
Two notes: First, I’m hiring for a couple of very special roles, to work closely with me on crypto products at Shopify. See the end of this newsletter to learn more.
Second: Today’s newsletter is a partnership special: I’m filling in for Mario Gabriele at The Generalist, who is off this week and kindly offered me the opportunity to write a guest issue. So today will be something a little different from what I usually write: I’m going to tell you about a specific company I really admire, called Twist Biosciences. This essay will appear in both our newsletters this week.
Two necessary parts here, before we begin: first, this essay’s purpose is to inform, educate, and spark curiosity - not to give investment advice. Second, I personally own shares of Twist, so I am hardly an objective observer. I am a fan here, not an analyst. Don’t treat this essay as anything it isn’t.
Hope you enjoy it, and that you learn something!
-Alex

Art by ヤツデ, from https://www.pixiv.net/en/artworks/13461444
Last Friday, when Ginkgo Bioworks went public through a SPAC merger, was a joyful day for the synthetic biology community and for an ideological movement that you can best describe as "Solarpunk aesthetic." In contrast to today's parade of software IPOs, which are usually great companies but not particularly radical in the grand scheme of things, Ginkgo Bioworks and the Solarpunks have an actually wild and fascinating vision of the future that could be. It's the idea that we're going to build the future by growing living things. The movement has a name: synthetic biology.
The past thirty years of software have conditioned us to think about value creation through the lens of the infinite leverage of logic. There's no ceiling to how well-crafted the world's information and communication streams can be logically arranged; that's why we say that "Software is eating the world." If the solarpunks have their way, the next thirty years will show us the same thing is true for physical stuff, materials, fuel, and all kinds of work that can one day be bioengineered. Today we catch occasional glimpses, like this bioengineered fireproofing material for airplane wings, reminding us: "There's no reason we can't build a better version of anything, with the right tools and the right founders." And the arms race is on to build those tools.
That's why today, I'm not going to tell you about Ginkgo Bioworks, as awesome a company as they may be. I'm going to tell you about the platform behind them, a factory for building the DNA strands upon which all of life science is subsequently abstracted. That company is called Twist Bioscience. It's one of my favourite companies in the world.
Twist is a DNA factory. They start with inputs - the A, C, T and G chemical letters that make up the base-4 code for life on earth. And they produce outputs - sequences of DNA, called oligonucleotides, whose code gets compiled by cells into molecular products and molecular work. In that sense, they are a manufacturing company.
Twist is also a software company. Led by a brilliant founder, Dr. Emily Leproust, Twist isn't a traditional biotech success story - it's the beginning of a new kind of founder-led, product-oriented bio companies that look much more like tech startups than they do life sciences bets. Today, I'm going to tell you all about them.
Manufacturing DNA 101
In a rather literal sense, Twist is a DNA manufacturing company. So before introducing them properly, I want to take you through a primer (pun absolutely intended, IYKYK) of how we create this stuff.
How do you make DNA? The answer is, it depends. Specifically, it depends on whether you have some already. We're very good at Copy-Pasting DNA, but actually writing brand new DNA sequences is harder.
Copy-pasting existing DNA sequences that we already have is something we've more or less figured out: cells already know how to do it, and we know how to hijack cell machinery to do that work for us. It's a broad theme you'll find in biology generally: we're much better at borrowing life's tools that already exist than we are at building brand new ones.
There's one company in particular whose origin story is important to know: Genentech. If you don't know anything about biotech whatsoever, but you do know your Silicon Valley history, there's a good chance you've already heard of Genentech as the "original biotech home run", and helped cement KPCB as an elite VC fund in the 1970s.
Genentech showed that you can hijack existing cellular machinery called Restriction Enzymes (essentially, molecular scissors) to selectively cut out a gene from its genome, isolate it, and stick that gene in another cell, where it can operate and replicate. This technique, called "Cloning", was a huge step forward for molecular biology, and gave us products like synthetic insulin. The subsequent decades of progress in molecular biology largely built on that basic technique of Copy-Paste to do increasingly sophisticated things.
But what if you want to make a new DNA sequence? We can do Copy-Paste, but what about Write? Bad news: writing new DNA sequences from scratch is substantially harder.
The challenge here, fundamentally, is an assembly problem. Our inputs are a bunch of DNA bases - As, C, Ts and Gs, which we can chemically produce in bulk. Our output needs to be a DNA strand of those letters, assembled in exactly the right sequence that we want, without a template strand to copy off of. The basic process that we use to do this assembly, which we've known for decades, is called Phosphoramidite Oligonucleotide Synthesis. It's an intimidating name, but actually a pretty simple assembly process. I'll take you through it:
We start with our first letter, attached to a solid support like the bottom of a chemical test tube. Once we have our first letter, we're going to cycle through a series of chemical reactions that sequentially attaches letters, one by one:
First, we have "uncapping": we chemically remove a protecting cap on the top of the sequence. Then, the second chemical reaction is "coupling": we add our second letter through a chemical process that bonds it to the first letter. Then the third chemical reaction is "capping": we oxidize and protect the top of the sequence, to preserve the integrity of our strand, then wash everything out. Finally, we start again with the next letter.
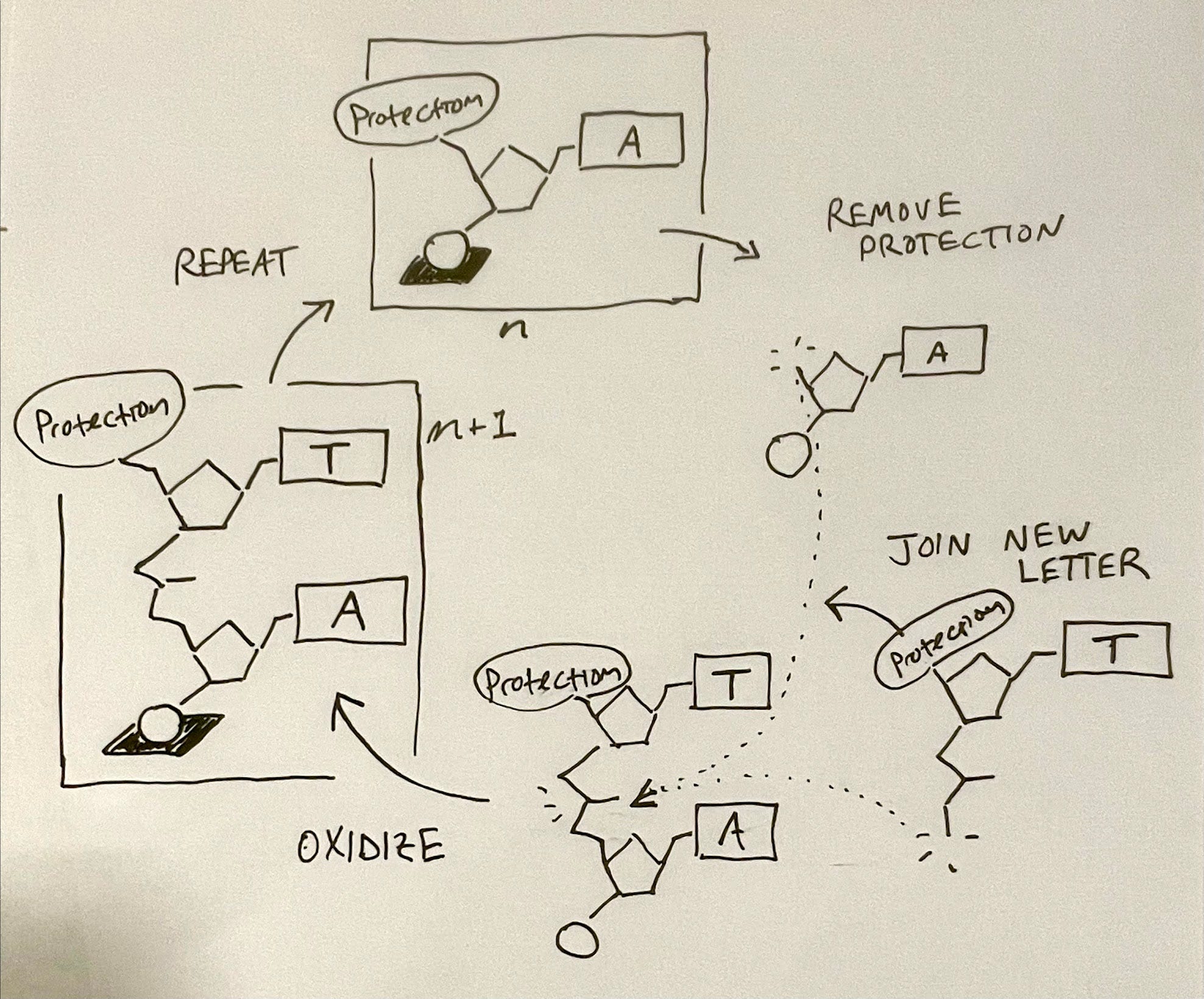
That's it! You now understand the basic assembly reaction of how we make DNA. It's pretty cool. But it's also hard, in two pretty predictable ways: cost, and quality control.
Our first challenge is cost. Remember that every time you're adding a letter to a sequence, that's three (really, four) chemical steps that you have to do in sequence. So when we think about costs, we have the cost of running a process to assemble them in the right order (lab equipment, and highly trained human labour), and then cost of the inputs themselves (the ACTGs plus other reagents that make the reactions go). And remember, every time you do a reaction to add a letter, you have to wash everything away following that step, so you can move onto the next step. So most of your inputs are getting wasted; literally washed down the drain.
With our traditional setup, if you're doing good chemistry and you're wasting as little as possible, and you have the whole setup pretty automated, you could get your all-in costs down to somewhere around a dollar per letter for a starting quantity of a gene. Sounds pretty cheap, right? Well, a typical gene might be somewhere around a few thousand letters. And in a typical design-build-test-repeat sequence of actually doing stuff with these DNA sequences, you'll go through hundreds if not thousands of them. Most of the work of biology doesn't deal with single sequences; it works with libraries of sequences upon which you do work in parallel. So you can see how this will get expensive quickly.
The second challenge is error rate. No chemical reaction is perfect; there is always some error just from the fussiness of thermodynamics. Again, if you're doing a really good job and your error rate each time you add a letter is, say, 1/10th of a percent error (really good!), that error adds up if you're trying to synthesize strands of DNA that are 100 base pairs long or more. Generally, the longer the length of sequences you're trying to make, the more error rate you're going to get; and that's a big problem: error-checking costs money, and losing yield costs money.
So, for a while, DNA synthesis was stuck being too expensive. It's not like it was especially hard; it just did not scale. You had to be an established academic lab or pharmaceutical company to be able to do it in sizeable quantities, and even then, it was still scarce enough that you had to ration out what you made. You couldn't waste any, and it's hard to innovate on something where you can't afford to waste the input materials.
But we understood, intuitively, how to get out of the cost trap: what if we could speed up the chemistry, not by making one oligo strand synthesized cheaper and faster, but instead by synthesizing huge arrays of DNA strands all at once? We tried a few fancy ways of making this work, like light-activated chemistry where you take a whole array of DNA strands and then selectively activate chemical reactions by shining light on and off in specific spots and sequences. But then we found inspiration from another technology that's much more everyday familiar: the inkjet printer.
Imagine if, instead of a sheet of paper that runs through your printer, you have a two-dimensional array of strand supports, with DNA sequences growing off of each one. You can imagine an inkjet printer head, filled up with A, C, T and Gs, then darting around the page dropping its cargo in tiny, targeted chemical reactions across the entire array, in tiny quantities.
This is appealing for two obvious reasons: first, if you could inkjet-print huge arrays of DNA strands, you can multiplex them: you can ask for 100 unique strands, or 50 of one and 50 variants, or anything you like. The printer will just print whatever you tell it. Second, if you get the engineering right, your chemical reactions can take place with fewer reagents per letter addition - one to two orders of magnitude less than before. So you have a lot less waste, and so a lot less input cost of raw materials. This method promised much lower costs: paying cents per base pair, not dollars.
What's the catch? There's always a tradeoff, and in this case, the tradeoff was error rate. The inkjet printer method was simply not as reliable as the old school way. But a few businesses got to work improving the process, notably a company called Agilent, where one of their scientists, Dr. Emily LeProust, was cracking the puzzle of how to get it all: large custom arrays, long sequences, high quality, and low price.
Twist: The DNA API Business
In 2013, LeProust left Agilent and started a new company, along with cofounders Bill Banyai and Bill Peck, called Twist Biosciences. (The dispute of whether or not she took any proprietary knowhow with her was not settled until years later.) They've had quite a ride since.
Twist is conceptually easy to understand: it's DNA manufacturing as a service. And Twist is good at it: they took the inkjet printer metaphor to its logical extreme, which is how silicon chips are made at fabs. They print thousands of DNA oligo sequences at a time, on silicon chips, with very low error rates. Then they package them up and send it all to you in the mail. The whole process takes a few days, from order sequence in to high-quality DNA out. They don't have the business all to themselves; there are competitors like IDT, GenScript, GeneArt and Genewiz.
It’s still a “small” business, as far as big platform companies go, but it’s accelerating: they made $35 million of revenue in Q2 2021, at 44% gross margin, up from $21 million at 22% gross margin the year prior. They’re also still definitely operating as a startup; they’re burning $42 million a quarter, with $400 million available from a recent equity raise. So this is a startup that is absolutely shoveling money into growth, especially as they establish their new “Factory of the Future” near Portland that will dramatically increase their DNA synthesis throughput.
So this is well outside “Rule of 40” territory (The rule of thumb for growth tech companies, suggesting y/y growth rate plus profit margin should equal at least 40%). But the fact that they invite the comparison at all is what matters here: this is not a software company selling SaaS seats; this is a company that will have to spend a whole lot of money to make money. In all likelihood, you could only build Twist in a discount rate environment like today.
But we’ll take it: enough shareholders believe that this company should trade like a software company, not a biotech company. (It currently trades north of 30x sales). Part of it is real belief in the possibility of a synthetic biology inflection point coming soon, with Twist as a call option on the story that will come. Part of it is the stickiness of the revenue, which isn’t recurring revenue strictly speaking, but isn’t far off.
But even today, there’s another meaningful way that Twist is more comparable to a growth-stage tech company than to a manufacturing company: its product. Because Twist is an API business.
Although there are plenty of customers ordering DNA by hand, where a physical human in a lab somewhere is ordering sequences on Twist's website, that's not the real business at scale. The real business starts when it all automates. Twist's best customers, like Ginkgo Bioworks, are building modern biology factories: and that means machines making decisions, and communicating with other machines.
Here's where it's important to understand one way that bioengineering and software engineering are different: biologists get things done through massive parallel attempts much more explicitly than software engineers do. When bioengineers program a new cell line to do molecular work, that kicks off a process that likely loads thousands of "build cycles" in parallel, which we try to automate as much as possible. Here's why it's so important that Twist is an API company: this only actually works at scale if machines can take over the process below a certain level of abstraction, and talk directly to each other.
"Level One" of Twist's business, if you want to call it that, is the DNA ordering through API call product. It's a good product. But it's just the beginning; it's like EC2 from AWS. And just like AWS, which many people did not understand and value correctly at first ("It's just charging me for generic CPU cycles on someone else's computer? Who would pay for this? We've got on-premise machines 1000x times as powerful!"), a lot of incumbent biotech people did not see Twist as all that interesting when they launched. Here's a representative quote from 2015:
"The promise of mass-produced DNA doesn’t impress Rob Carlson, a biotech consultant and managing director of the BioEconomy Capital venture fund. “I don’t understand the business model,” he says. Carlson is skeptical that cheap DNA assembly will lead to a proliferation of startups with ideas for profitable microbes. “So you can make and test a whole bunch more DNA—but that’s not the hard part,” he argues. “Going from test tube to bench scale to commercial scale, that’s 90 percent of cost.” For a startup to build a business around a yeast that cranks out a pharmaceutical, for example, it must manage massive tanks full of microbes. Reducing the cost of the initial DNA manufacturing would only give the company pocket money, Carlson says: “Hooray, they get to buy beer, or more pizza on Friday.”
Of course, anyone who comes from the software world can see where this is going. The cloud isn’t, in fact, just “someone else’s machine”; it’s a different build mindset. The cloud isn’t something you use; it’s something you do.
But even before we get to Twist's really disruptive impact, it's worth mentioning the "Level 2" businesses they're building on top of their oligo product, which are pretty impressive in their own right. Remember how much of the work of bio-building is through massive parallel attempts? Twist doesn't just want to sell you the DNA for those attempts, they want to sell you the input libraries of variants that go into those parallel build cycles.
If you go to Twist's product page now, you'll see products like Oligo Pools and Variant Libraries, which are basically input products to The Massive Parallel Build, as opposed to fulfilling individual commodity oligo orders. They're steadily moving up to higher and higher levels of abstraction, as they start going after some of commercial big guns: antibodies, immunotherapy, and other next-generation therapeutics that achieve outcomes through programming cells, rather than old-school therapeutics development. That's why ten years from now, we may well consume a whole host of products with Twist DNA quietly inside of them, just like today consume the internet without knowing which cloud providers are behind what.
But Twist's real potential isn't to improve the biotech back end. It's changing the biotech game entirely.
The Bio Founder, and the beginning of Product-Market Fit in Biotech
So what's the real point of all of Twist, in the grand scheme of things? It's not just DNA-as-a-service, or their library of libraries business. The opportunity is to catalyze a generational transformation in how life sciences companies are started and grown.
Every complex ecosystem, and every organizational paradigm, started from an origin crystal. And the particulars of that origin crystal - exactly how it started, what it looked like, what worked, and why - become a template that gets copied for generations - at some point, without anyone knowing what they're even copying.
Our modern software industry began this way, with the "Traitorous Eight" who left Shockley Semiconductor to found Fairchild Semiconductor, and subsequently Intel. These companies were born out of an understanding - between two founders, Bob Noyce and Gordon Moore, and one investor, Arthur Rock - that the founders were the capital of the business. This was a more radical idea at the time than people today can really understand, and it established a model for how to build founder-led, venture backable companies. Today, the entire startup industry is geared around the founder as the scarce resource.
But not biotech. Biotech has a different origin story, which we mentioned earlier: Genentech. Genentech was founded as a partnership between a scientist at a lab (Herbert Boyer) whose job was science, and a Venture Capitalist (Bob Swanson) whose job was commercialization. Nearly every biotech startup since has followed a similar model. Biotech does not really have the singular concept of "Founders" the way that software does: there are the Scientists, led by a Principal Investigator, whose job is mitigating technical risk; and there is Management, whose job is commercial development.
There are many reasons why the Biotech Scientists + Management setup evolved the way it did: a different risk profile, different costs, the cultural attitudes around the "purity" of scientific research, and just generally the "We shape our tools, and they shape us" mechanic. Once biotech VCs learned how to finance bets that way, then that's what the bets became. But this separation came at a huge hidden cost: it virtually precludes, right from the beginning, the potential for founders to forge product-market fit that doesn't yet exist.
That's why the only biotech companies you've ever heard of, in all likelihood, make therapeutics. You don't need to craft product-market fit if you're making an Alzheimer's drug; it either passes trials or doesn't. You don't need a founder to develop drugs. But you do need a founder if you want to build entirely new things.
The problem with the biotech industry, up until recently, was that there was no real path to becoming a founder. Your startup costs were high enough that the only path in was to start with a lab and VC funding, and follow the tried-and-true commercial spinoff model that biotech knows how to do.
This is why companies like Twist are so important. They make it easier to become a founder, and they open the funnel for builders to build. Tony Kulesa wrote a fantastic post a few weeks ago called The Future of Biotech is Founder-Led, which highlights what's going on perfectly: biotech is finally reorienting around a new way to build companies, pioneered by the software world. This world isn't run by scientists and management teams: it's run by founders, and by developers.
You may remember a few years back, Twilio had an advertising campaign: "Ask your developer!" If you look at companies like Twilio, Stripe, Plaid, and all these other amazing API companies, the right way to understand them from the beginning was: "They make founders and developers more productive." They can try things faster, and they can forge product-market fit more quickly.
That's what Twist is doing for bio founders, bio engineers, and the whole biology startup community. They're your DNA cloud infrastructure where you get started, the silent partner behind your quest for product-market fit, and the robot factory that scales with you, as you grow like Ginkgo. Twist is becoming one of a handful of companies that opens the door for biologists to build. And in the 21st century, so many of our biggest problems can't be solved digitally; they must be solved through physical matter, and finding new ceilings for how well we can build the world around us. I can't really think of too many companies with a more important mission than that.
Permalink to this post is here: Twist Biosciences, the DNA API | alexdanco.com
One more thing, before we go: I’m hiring for a couple of special roles on the blockchain team at Shopify.
If you’ve read my newsletter for a little while, I think you have a sense for how I like to think about the world: I love to think about systems, I love thinking about complexity, about change, and especially about the people inside those changing systems. There’s nothing more professionally rewarding in the world than getting a small, special group of people in one place, with a shared purpose, to go explore and build together.
There’s no doubt, in my mind, that we are currently at the beginning of Crypto’s Eternal September. There is no more “crypto community” versus “everybody else” anymore; not for long, anyway. And Shopify could have a really interesting role to play in what happens next.
Over the past few months, we’ve gathered together a small and awesome team inside of Shopify to go figure this out. And I want to extend an invitation to all of you (well, the devs among you anyway, for the time being) to join us.
Curious? For a description of what we’re looking for, and how to get in touch, head here.
Have a great week,
Alex